
![]()

![]()
Contents
Description
Handwriting recognition is an open research topic in the document analysis community. A particular application is the bank check processing. Although many people have predicted the death of bank checks as means of payment, there are many countries that still use them for financial transactions. Moreover, in the last years the financial sector has been concerned about replacing paper checks by electronic images. This is known as the check truncation process aiming to save time and processing cost.
In order to bank check processing become a complete automatic process there are many challenging tasks that require to be solved. One of these tasks is the automatic recognition of the CAR field. The CAR field consists of a sequence of digits together with a combination of special numeric symbols representing a monetary value. Although in the last years diverse methods have been proposed to face the recognition of the CAR field, none of them has demonstrated yet high accuracy under noisy images. In addition, to our knowledge, there is no an evaluation dataset representing images as they can be found in real environments. Two examples of handwritten digit strings captured from the CAR field of bank checks are shown below:
![]()
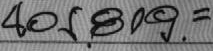
Two examples of CAR fields extracted from real bank checks.
As it can be noticed, real CAR images bring with a variety of noise like background patterns, check layout (lines or monetary symbols), or user strokes. The noise appearing on a CAR field image turns the recognition problem a very challenging problem. In addition, the natural variability of the handwritten text represents another challenge that we must deal with. Unfortunately, it is a common practice to evaluate proposed methods with images generated “inside a laboratory” which are far from the images that one could find in real applications. Consequently, the published performance of a certain method is very different from the performance obtained when the method is evaluated in real environments.
Therefore, the objective in this competition is to evaluate different approaches for the handwritten Arabic digits strings of images captured from the real world. To this end, we will release a CAR dataset extracted from real bank checks and the digit strings of the CVL database.
The first dataset (CVL Database) has been collected mostly amongst students of the Vienna University of Technology and consists of about 300 writers, female and male alike. The second dataset (ORAND-CAR-2014) consists of digit strings of the courtesy amount recognition (CAR) field of bank checks. We expect these datasets will be very worthy to researchers, allowing them to evaluate, in a more accurate manner, the performance of underlying proposal methods. Indeed, using images from real applications allows us to get a more accurate performance value about the behavior of a certain method in real applications.
People
Vienna University of Technology, Austria
Orand S.A, Chile
- Jose M. Saavedra
- Juan Manuel Barrios
- David Contreras
Federal University of Parana, Brazil
Datasets
Please, if you use one or both of the following datasets, cite this paper:
“Markus Diem, Stefan Fiel, Florian Kleber, Robert Sablatnig, Jose M. Saavedra, David Contreras, Juan Manuel Barrios, Luiz S. Oliveira. ICFHR 2014 Competition on Handwritten Digit String Recognition in Challenging Datasets (HDSRC 2014). In Proceedings of the International Conference on Frontiers in Handwriting Recognition, ICFHR 2014. Greece.”
ORAND-CAR-2014
The ORAND-CAR-2014 dataset consists of approximately 10,000 CAR images extracted from real bank checks with a resolution of 200 dpi. The dataset contains approximately 5000 images for training purposes and 5000 images for testing.
Download ORAND-CAR-2014 dataset [194 MB].
You might want to compare the SHA256 checksum or the MD5 checksum for these files.
The ORAND-CAR-2014 dataset is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.

The CVL Database
The CVL Database has been collected mostly amongst students of the Vienna University of Technology and consists of about 300 writers, female and male alike. The images will be delivered in original size with RGB information and a resolution of 300 dpi. The digits are provided in the original size, since in real world cases, the writers’ styles include variation in size as well as writing style. This new database will pose new challenges to the community since we believe it is harder than previously published datasets, especially in terms of variance in writing style.
The CVL database of digit strings is created for recognition and segmentation purposes. For each writer, 26 different digit strings with varying length were collected. Of each string, 300 samples are provided resulting in a database with 7800 samples. When setting up the database, a uniform distribution of the occurrences of each digit was ensured. Of the whole set, a training set will be randomly chosen with the constraint that only a subset of writers will be presented in the training set in order to prevent over-fitting of the contributing algorithms and test for their ability of generalization.
Download CVL dataset: For training [15.1 MB] and testing [79.1MB].
Evaluation
There are two kinds of evaluation metrics, a hard metric and a soft metric. In the case of the hard metric, we will evaluate the recognition rate. That is, the number of correctly recognized amount images divided by the total number of amount images. In this evaluation, we will allow the participants to submit the TOP-3 answers for each amount image, representing the three best responses of an underlying method. Therefore, we will evaluate the recognition rate for TOP-1, TOP-2 and TOP-3.
Considering that the test images may be affected by noise, the recognition rate may be very low for many methods. To deal with this problem, we also propose a soft metric that evaluate how close a resulting answer is to a target amount. Since the text written on the CAR field is, in fact, a string, our soft metric is based on the Levenshtein distance (LD). This distance is also known as the Edit Distance. In particular, we will use the Normalized Levenshtein Distance (NLD) to avoid any bias with respect to the amount length.
Let 


=\frac{min(LD(a_T, a_R), |a_T|)}{|a_T|},")
where 


We also define the Average Normalized Levenshtein Distance (ANLD) as below:
}{T},")
where 
Our proposed evaluation metrics are summarized below:
- Recognition Rate for TOP-1.
- Recognition Rate for TOP-2.
- Recognition Rate for TOP-3.
- Average Normalized Levenshtein Distance using TOP-1.
Submission
Registration
In order to participate in this competition, each team must send an e-mail to hdsrc@caa.tuwien.ac.at until 28.02.2014, including:
- Subject: [ICFHR2014-HDSR]
- Author names and affiliation
- Short description of the method submitted
- References of the method submitted, if available
Submission Procedure
Participants must submit a zip file, containing the binary program together with all dependencies, for each proposed method to hdsrc@caa.tuwien.ac.at . Please, name the zip file using the following syntax:

In addition, all submissions must include a README file giving details of the platform used for executing the underlying program.The binary program must receive two arguments as:

: filename of the input RGB/GRAY image (the digit string)
: filename of the output text file containing the first three digit string guesses separated by a comma “,”
Please, do not forget to provide all dependencies with your binary.
Results
Results will be announced by May 12th.
Important Dates
– Registration: until Feb 28th, 2014
– Database Releasing:
– CVL Database:
– ORAND-CAR-2014 dataset:
– Binary Submission: March 25th, 2014
– Result Announcement: May 12th, 2014
Contact
Robert Sablatnig, CVL, Vienna University of Technology
Jose Saavedra, CVRG, Orand S.A.
e-mail: hdsrc@caa.tuwien.ac.at